
Think of pipelines as templates that can have multiple executions going on in parallel. Ideally, every single commit that ends up in the repository is a new change you would like to run the pipeline against. Stages are the processes you would like to avoid concurrent executions for. For example, you don’t want to deploy two different commits to the dev environment in parallel. Soon after the deployment completes, you would want to run some tests against the same code. Let’s say you pushed two commits, 3eedg457 and 7634hhhf, in sequence – you would want to both deploy and test, for a singlecommit at a time, before proceeding to the next one. This is what qualifies as two different operations combined in a single stage, thus isolating concurrent executions from one another.
Actions – operations you perform within a stage
Several action types are supported by CodePipeline, including Source, Build,Deploy, Approval, and others. You can combine them, run them in sequence, or parallelize them based on your needs. For each of the actions, you have some providers supporting them in the background. For example, for Source, the code could be coming from S3, Amazon ECR, or even CodeCommit. Similarly, for Test, you could be running CodeBuild, BlazeMeter, or even Jenkins jobs.
A good visual representation is provided in Figure 5.1:
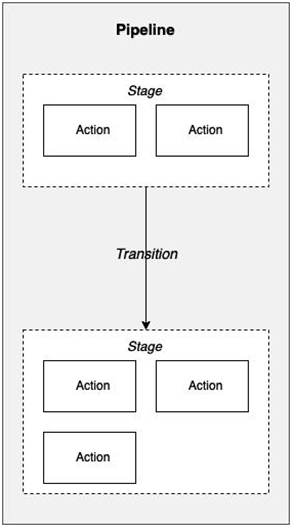
Figure 5.1 – Modeling stages and actions in a pipeline
Tip
In addition to the action providers supported by CodePipeline, you can also create your own. The service offers a framework to create and register action providers for one of the supported categories – that is, test, deploy, and so on. You can write your own Lambda function that receives such invocations from CodePipeline and leverage it to bridge any automation needs with the outside world.
Next, let’s discuss how we can link several stages together to form a logical workflow, also known as a pipeline.
Pipeline executions – releasing code changes as they happen
You can refer to each pipeline execution with a unique ID that corresponds to the respective executions in the downstream services. As discussed previously, every stage is isolated from other executions that might be happening in parallel. Apart from this, multiple pipeline executions can be in flight at the same time, covering different stages in each.
Artifacts – data consumed and produced by actions
Artifacts are a core component of an entire pipeline’s execution. This is the data that gets passed between different action providers – entirely orchestrated by the service. You don’t have to manage S3 object creations, versioning, and other configurations. All of this is taken care of by CodePipeline. It uses an artifact bucket, which is more or less a message bus that offers data transmission between different operations.
We will see most of these constructs in action in the next section when we work with CloudFormation templates to roll out a pipeline in our AWS accounts. Before getting to that, though, let’s discuss an underrated feature of CodePipeline – cross-region actions.